Web Scraping with PowerShell
Sometimes you end up in situations where you want to get information from an online source such as a webpage, but the service has no API available for you to get information through and it’s too much data to manually copy and paste. Or maybe you need to register a lot of entries on a website, but don’t have a bored friend to help out. Fear not, PowerShell can be your bored friend if you ask nicely!
If you’re using PowerShell 7 or higher you might not be able to run all examples in this post without modification, as the way that web requests parse the data has been changed.
PowerShell and Web Content
PowerShell has several ways of getting data from a source on the web, be it a normal webpage or a REST API. There are two cmdlets available to make web requests, and PowerShell also of course has access to everything that .NET has to offer. If neither Invoke-WebRequest or Invoke-RestMethod is good enough you can dig into System.Web and build solutions using that. You may encounter cases where encoding doesn’t work as expected, and making your own functions with classes from .NET can be one way of solving it.
Invoke-WebRequest
Invoke-WebRequest is just what it sounds like, it creates and sends a request to a specified web address and then returns a response. Think of it like opening a web page in your browser, you get all the HTML on the address you put in but also all the metadata that the browser handles for you to present the site.
PipeHow:\Blog> Invoke-WebRequest 'www.google.com'
StatusCode : 200
StatusDescription : OK
Content : <!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="sv"><head><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta...
RawContent : HTTP/1.1 200 OK
X-XSS-Protection: 0
X-Frame-Options: SAMEORIGIN
Cache-Control: private, max-age=0
Content-Type: text/html; charset=UTF-8
Date: Mon, 14 Oct 2019 16:57:41 GMT
Expires: -1
P3P: CP=...
Forms : {f}
Headers : {[X-XSS-Protection, 0], [X-Frame-Options, SAMEORIGIN], [Cache-Control, private, max-age=0], [Content-Type, text/html; charset=UTF-8]...}
...
You can see that there is a lot of metadata returned with the response. Using Invoke-WebRequest you get everything from the content of the web page to the HTTP status code to see what the server said about your request. This is useful but not always needed, sometimes we only want to look at the actual data on the page, stored in the Content property of the response.
We can of course save the response in a variable and expand it to get our data, but if we’re not going to use the metadata at all, there’s another cmdlet that we can use.
Invoke-RestMethod
Invoke-RestMethod behaves and is used in the same way as Invoke-WebRequest, the big difference is that you only get the content and no metadata. If the data is in JSON, it will also automatically parse it into an object. This is especially handy when working with REST APIs that respond with data in JSON, and removes the need to run the content of the response through ConvertFrom-Json afterwards.
PipeHow:\Blog> Invoke-RestMethod 'www.google.com'
<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="sv"><head><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content=...
We ran the same command, but this time we only got the actual HTML data of www.google.com. If we take a quick look at a site that has an API with more structured information, we can see the difference more clearly.
I like using the JSONPlaceholder API when demonstrating API requests, it’s a fake API that can be used to test your code.
PipeHow:\Blog> Invoke-WebRequest 'https://jsonplaceholder.typicode.com/posts/1'
StatusCode : 200
StatusDescription : OK
Content : {
"userId": 1,
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"body": "quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nrepr..."
RawContent : HTTP/1.1 200 OK
Connection: keep-alive
Vary: Origin, Accept-Encoding
Access-Control-Allow-Credentials: true
Pragma: no-cache
X-Content-Type-Options: nosniff
CF-Cache-Status: HIT
Age: 4743
Expe...
Forms : {}
Headers : {[Connection, keep-alive], [Vary, Origin, Accept-Encoding], [Access-Control-Allow-Credentials, true], [Pragma, no-cache]...}
Images : {}
InputFields : {}
Links : {}
ParsedHtml : mshtml.HTMLDocumentClass
RawContentLength : 292
PipeHow:\Blog> Invoke-RestMethod 'https://jsonplaceholder.typicode.com/posts/1'
userId id title body
------ -- ----- ----
1 1 sunt aut facere repellat provident occaecati excepturi optio reprehenderit quia et suscipit...
Calling the cmdlets side by side makes it more clear as to what the differences are. If we take a look at the Content of the data we got from Invoke-WebRequest we see that it’s a simple JSON string, while what we got from Invoke-RestMethod has already been converted to a PSCustomObject with properties parsed from the JSON data.
Browsing Websites using PowerShell
Now that we know how to get data from the web, let’s dive deeper to find out how we can parse data, click buttons and keep an active session after logging into a website.
Just like the fake API from the previous example there are many sites online simply for the purpose of testing web scraping, we’ll use Quotes to Scrape which has a login feature.
Parsing Data
If we look at the site using a browser we can see that it’s split up into a bunch of quotes, with tags and an author.
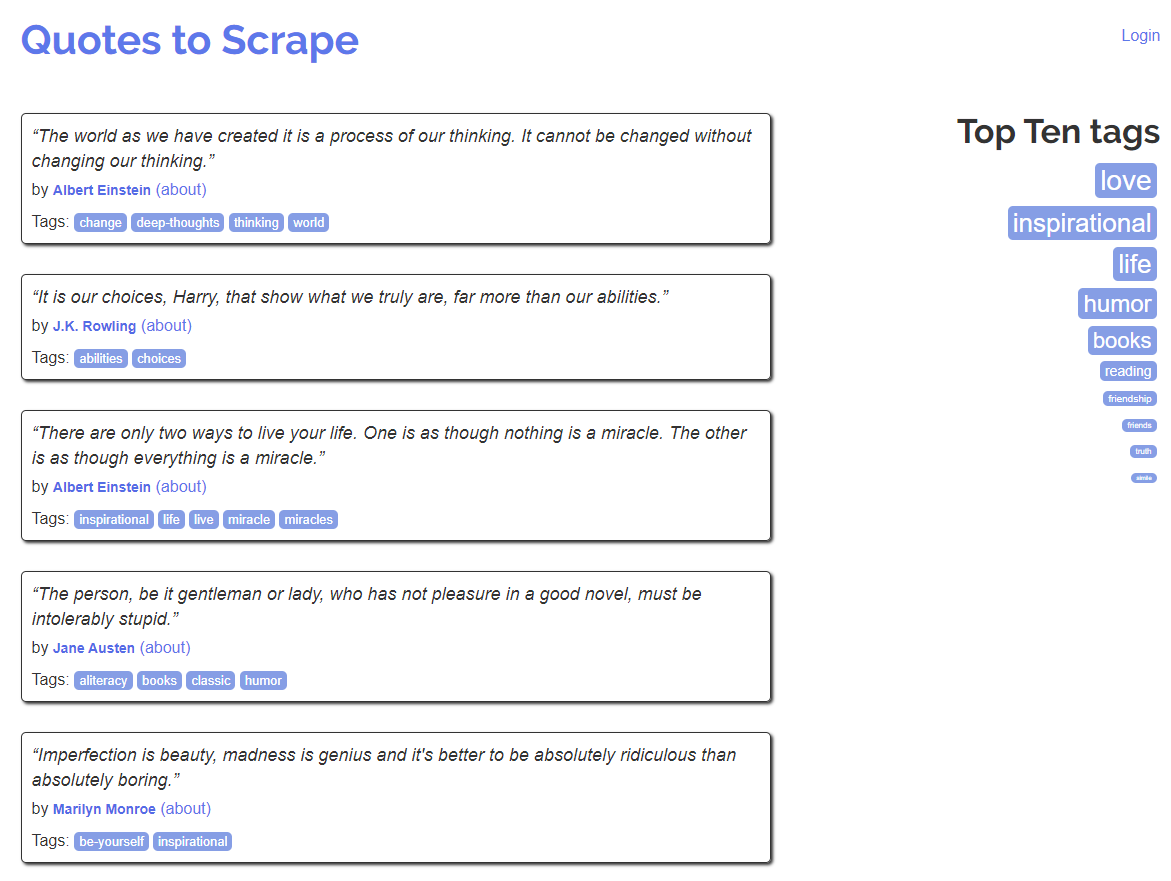
Let’s set our goal to getting all quotes on the first page, saving the quote and its author and tags to a list. To do this we will need to parse the HTML, and doing that in the most efficient way is by using Regular Expressions, or regex.
Looking at the HTML of the site in either PowerShell or by using a browser we can find out the structure of each quote.
<div class="quote" itemscope itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world" / >
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
- The quote is in the first
<span>tag. - The author is in the
<small>tag. - The tags are in the content attribute of the
<meta>tag.
Knowing this lets us create a regular expression to gather these values from a pattern, which we can use with the -match operator in PowerShell.
PipeHow:\Blog> $HTML = Invoke-RestMethod 'http://quotes.toscrape.com/'
PipeHow:\Blog> $HTML -match '<span class="text" itemprop="text">.*</span>'
True
PowerShell returns true or false whether or not we find a match, and also stores any matches in a hashtable called $Matches automatically. The pattern above matches the text as . means “any character” and * means “zero or more times”. We can look at the automatic $Matches variable to verify our results.
Name Value
---- -----
0 <span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
We can do better though, to filter out exactly what we need we can create a so-called named group.
PipeHow:\Blog> $HTML -match '<span class="text" itemprop="text">(?<quote>.*)<\/span>'
True
If we now run $Matches again we can see that it has a new value which we can reference by name and get the value from.
Name Value
---- -----
quote “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
0 <span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
Using the same procedure we can create a pattern that gathers all values that we want in named groups, according to the HTML structure of each quote on the page:
- Match a named group for the quote in the
spantag, followed by a new line with anything on it. - Match a named group for the author in the
smalltag, followed by 5 new lines with anything on them. - Match a named group for the tags in the
contentattribute of themetatag.
I won’t go deep into how regex works in this post, that’s for another time, but the following pattern matches the structure of each quote.
PipeHow:\Blog> $Pattern = '<span class="text" itemprop="text">(?<quote>.*)<\/span>\n.*<small class="author" itemprop="author">(?<author>.*)<\/small>(\n.*){5}<meta class="keywords" itemprop="keywords" content="(?<tags>.*)"'
PipeHow:\Blog> $HTML -match $Pattern
True
This lets us find the text in each of the patterns we defined earlier.
Name Value
---- -----
quote “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
tags change,deep-thoughts,thinking,world
author Albert Einstein
1 ...
0 <span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>...
The problem is that even when we run it on all our HTML data we only get a single quote matched, this is because -match only returns a single match, the first one. There are other ways to match by regex in PowerShell as well which lets us get all matches, we can either use Select-String with the parameter -AllMatches and then look at the Matches property of the return value, or run the .NET version [regex].
PipeHow:\Blog> $AllMatches = ($HTML | Select-String $Pattern -AllMatches).Matches
PipeHow:\Blog> $AllMatches = ([regex]$Pattern).Matches($HTML)
Both of the commands above result in equal results. Each match comes with some metadata such as length and index in the total string.
Groups : {0, 1, quote, author...}
Success : True
Name : 0
Captures : {0}
Index : 797
Length : 454
Value : <span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world"
We’re only interested in the matched named groups, so all we need is some magic to get those from each quote. To do this we can loop through all matches and save a custom object of each quote to an array, and we’re done.
$QuoteList = foreach ($Quote in $AllMatches)
{
[PSCustomObject]@{
'Quote' = ($Quote.Groups.Where{$_.Name -like 'Quote'}).Value
'Author' = ($Quote.Groups.Where{$_.Name -like 'Author'}).Value
'Tags' = ($Quote.Groups.Where{$_.Name -like 'Tags'}).Value -split ','
}
}
Looking at the $QuoteList we can now see all of the different quotes, with their authors and the tags from the site split from each other into an array.
Quote Author Tags
----- ------ ----
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” Albert Einstein {change, deep-thoughts, thinking, world}
“It is our choices, Harry, that show what we truly are, far more than our abilities.” J.K. Rowling {abilities, choices}
“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.” Albert Einstein {inspirational, life, live, miracle...}
“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.” Jane Austen {aliteracy, books, classic, humor}
“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.” Marilyn Monroe {be-yourself, inspirational}
“Try not to become a man of success. Rather become a man of value.” Albert Einstein {adulthood, success, value}
“It is better to be hated for what you are than to be loved for what you are not.” André Gide {life, love}
“I have not failed. I've just found 10,000 ways that won't work.” Thomas A. Edison {edison, failure, inspirational, paraphrased}
“A woman is like a tea bag; you never know how strong it is until it's in hot water.” Eleanor Roosevelt {misattributed-eleanor-roosevelt}
“A day without sunshine is like, you know, night.” Steve Martin {humor, obvious, simile}
Interacting with a Website using PowerShell
So far we’ve gotten data from a website and then looked at or formatted it locally in PowerShell, but sometimes there are cases where the data is locked behind a click. Sometimes you need to log into a website with your credentials before you can access the data, and doing that requires you to have an active session between your web requests.
You can manage a continuous session between requests with both of the cmdlets that we’ve gone through, but you will have an easier time managing things such as entering information in fields and clicking buttons if you use Invoke-WebRequest because of the extra information that it returns.
Let’s use the same site again and try looking at our options for logging in.
PipeHow:\Blog> $URL = 'http://quotes.toscrape.com'
PipeHow:\Blog> $Site = Invoke-WebRequest $URL
PipeHow:\Blog> $Site
StatusCode : 200
StatusDescription : OK
Content : <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/m..."
RawContent : HTTP/1.1 200 OK
Connection: keep-alive
X-Upstream: spidyquotes-master_web
Content-Length: 11053
Content-Type: text/html; charset=utf-8
Date: Thu, 17 Oct 2019 18:59:39 GMT
Server: nginx/1.12.1
...
Forms : {}
Headers : {[Connection, keep-alive], [X-Upstream, spidyquotes-master_web], [Content-Length, 11053], [Content-Type, text/html; charset=utf-8]...}
Images : {}
InputFields : {}
Links : {@{innerHTML=Quotes to Scrape; innerText=Quotes to Scrape; outerHTML=<A style="TEXT-DECORATION: none" href="/">Quotes to Scrape</A>; outerText=Quotes to Scrape; tagName=A; style=TEXT-DECORATION: none
; href=/}, @{innerHTML=Login; innerText=Login; outerHTML=<A href="/login">Login</A>; outerText=Login; tagName=A; href=/login}, @{innerHTML=(about); innerText=(about); outerHTML=<A href="/author/Alber
t-Einstein">(about)</A>; outerText=(about); tagName=A; href=/author/Albert-Einstein}, @{innerHTML=change; innerText=change; outerHTML=<A class=tag href="/tag/change/page/1/">change</A>; outerText=cha
nge; tagName=A; class=tag; href=/tag/change/page/1/}...}
ParsedHtml : mshtml.HTMLDocumentClass
RawContentLength : 11053
Here we can see that we seem to have no forms to fill out and no input fields, but we do have some links. If we look back to how the site looks we can see that there is a link that leads to a login page. There are a ton of links so I won’t list them all, but we can filter out the one we want. We could also use the links to click the “Next” button to implement paging of all the quotes on the site.
Something to be aware of is that the properties Forms and InputFields may still have content even if it doesn’t display when looking at the object itself. Let’s have a look at the link and also make sure we’re not missing any fields to fill on the launch page.
PipeHow:\Blog> $Site.Forms
PipeHow:\Blog> $Site.InputFields
Looks like there are actually no forms or fields. This matches our expectations since there are no visible ones when visiting the main page in a browser either, but it’s a good habit to look through the properties so we know what we have to work with.
PipeHow:\Blog> $Site.Links | Where-Object innerText -eq 'Login'
innerHTML : Login
innerText : Login
outerHTML : <A href="/login">Login</A>
outerText : Login
tagName : A
href : /login
We can see that our link has a property called href, if you’ve ever written HTML you probably recognize it as the destination for a link. This is in fact just normal HTML that PowerShell has parsed into an object for us, making it more convenient to browse the content.
We will use the href value of the link we found and simply add it onto our base URL in a string, then use Invoke-WebRequest again onto our new compounded URL. Then we’ll have a look at the properties to see if we can find any new fields or forms. Let’s also take the opportunity to create a continuous web session that we will use for future web requests, this is done using the -SessionVariable parameter in which we specify the name of a variable we want to store our new session in, in our case we’ll have a new variable called $DemoSession afterwards.
PipeHow:\Blog> $LoginPath = ($Site.Links | Where-Object innerText -eq 'Login').href
PipeHow:\Blog> $Site = Invoke-WebRequest "$URL$LoginPath" -SessionVariable DemoSession
PipeHow:\Blog> $Site | Select-Object Forms,InputFields
Forms InputFields
----- -----------
{} {@{innerHTML=; innerText=; outerHTML=<INPUT type=hidden value=WpjJfhEq...
There are definitely some new input fields, but there are actually some hidden forms as well. Forms are generally the way of entering data onto a website, so we want to look for those when trying to log into sites using PowerShell, by accessing the Forms property.
Id Method Action Fields
-- ------ ------ ------
post /login {[csrf_token, FecIyGWJSHgUQxjdELtpZwBbkMhOKrRYunCDsTmAfNoaiqzvPVXl], [username, ], [password, ]}
There are a few interesting things to note here. Firstly, it shows that the Action of logging in is using the same URL as we just browsed to, this action is what happens when a user clicks the login button in the browser. Actions, just like links, have a path that adds onto the base URL of the website. We can also see that it uses the HTTP method POST which is used when you want to send data back to the web. This seems promising, so let’s see if we can set the username and password. This website actually accepts any values since it’s for testing only, so our input doesn’t matter.
Something more to note is that the Forms property is actually a list, so to make sure to get everything right we will access the fields of the first form found on the page, which also happens to be the only one. You access the fields just as you do with values in a hashtable.
PipeHow:\Blog> $Site.Forms[0].Fields['username'] = 'PipeHow'
PipeHow:\Blog> $Site.Forms[0].Fields['password'] = 'AnyPasswordWorks'
PipeHow:\Blog> $Site.Forms[0].Fields
Key Value
--- -----
csrf_token FecIyGWJSHgUQxjdELtpZwBbkMhOKrRYunCDsTmAfNoaiqzvPVXl
username PipeHow
password AnyPasswordWorks
Great! Now all we need to do is post this back to the website and make sure to use the session that we created so that we can keep browsing the site once logged in. The body of the post will be the entire modified response of the previous web request, in our case our $Site variable that we’ve added our credentials into.
PipeHow:\Blog> $Action = $Site.Forms[0].Action
PipeHow:\Blog> $Site = Invoke-WebRequest "$URL$Action" -Method Post -Body $Site -WebSession $DemoSession
Even though the login action had the same path as our previous link, I used the action as part of the URL instead. This is to be extra clear since they’re not necessarily the same.
If everything worked as expected, as it does in the browser, we should have been redirected to the main page with one of the links now being “Logout” instead.
PipeHow:\Blog> $Site.Links | Where-Object innerText -eq 'Logout'
innerHTML : Logout
innerText : Logout
outerHTML : <A href="/logout">Logout</A>
outerText : Logout
tagName : A
href : /logout
We successfully logged in! We can keep using our web session to navigate deeper into the site if we like, and we’ll keep being logged in as we do. Let’s click another link such as the “Next” one and see if we still have the logout button, that means we kept our session.
PipeHow:\Blog> $Site.Links | Where-Object innerText -like 'Next*'
innerHTML : Next <SPAN aria-hidden=true>→</SPAN>
innerText : Next →
outerHTML : <A href="/page/2/">Next <SPAN aria-hidden=true>→</SPAN></A>
outerText : Next →
tagName : A
href : /page/2/
PipeHow:\Blog> $NextPath = ($Site.Links | Where-Object innerText -like 'Next*').href
PipeHow:\Blog> $Site = Invoke-WebRequest "$URL$NextPath" -WebSession $DemoSession
We’ll verify that we ended up on a different page by exploring the destination of this page’s “Next” button, and making sure that we still have a link to logout through.
PipeHow:\Blog> $Site.Links | Where-Object innerText -like 'Next*'
innerHTML : Next <SPAN aria-hidden=true>→</SPAN>
innerText : Next →
outerHTML : <A href="/page/3/">Next <SPAN aria-hidden=true>→</SPAN></A>
outerText : Next →
tagName : A
href : /page/3/
PipeHow:\Blog> $Site.Links | Where-Object innerText -eq 'Logout'
innerHTML : Logout
innerText : Logout
outerHTML : <A href="/logout">Logout</A>
outerText : Logout
tagName : A
href : /logout
The next page is number 3 and we can still log out! As long as we provide our session we can keep browsing while being logged in. We could even have several browsing sessions active at the same time using different variables, if we wanted to.
I hope you learned something new about working with web content in PowerShell, if you come up with a fun web scraping project you’re welcome to post a comment on how and what you did below!